
Deployment
Our MAPSS technology is deployed differently from typical websites and desktop design software approaches.
Physics engine
We developed a custom physics calculation engine which is more than a simple diffraction kernel, but instead, a collection of interoperable models to predict the behavior of light and matter at different size and timescales. Our physics engine was built with the following design principles:
Consistency
Definitions of physics concepts need to be consistent across different use cases and in different software modules. Consistency is key to enable an algorithmic approach to combining MAPSS modules. Our physics engine is built to ensure this consistency. For example, a wavelength used in one context must be equivalent to a wavelength in another context (Is it a vacuum wavelength or in a medium? Is the light coherent or not?).
Adjustable precision
Not every problem needs to be computed with the highest precision theory available. Our physics engine approximations to existing propagation and material interaction models, it is possible to accelerate the search for solutions in addition to the MAPSS technique.
Fast
In addition to being accurate, the coding in our physics engine supports efficient computation on modern processors. Not all problems lend themselves to large degrees of parallelization like ray propagation or diffraction. In the cases where parallelism is low or non-existent, our code is constructed carefully to avoid bottlenecks.

Synthetic Data Generation
Synthetic training data is generated by computation rather than being collected from existing sources or generated from human interactions. The advantage of using synthetic training data is that is avoids the legal and ethical concerns involved in harvesting other’s data without permission or attribution. We have taken into account the well-known limits on where and how synthetic data can be used for generating high-accuracy ML models, and have been able to exploit the benefits of this approach.
Control of sampling distribution
Synthetic data allows precise control over the sampling range and distribution used in training the model. Consider imaging problems, there are substantially more cases of imaging in the visible than the mid-IR range. Rules of thumb that apply in the visible range are less applicable in the mid-IR due to the difference in refractive index from the available materials. Synthetic data allows us to uniformly sample the transition from visible to mid-IR and thereby make a more accurate and efficient model.
Control of solution trade-offs
Every design is a balance of trade-offs. Understanding the priority of the design trade-offs is critical to understanding why a given design is acceptable. Synthetic data allows us to set the design trade-offs consistently and reduce the amount of training data required.
Managing costs
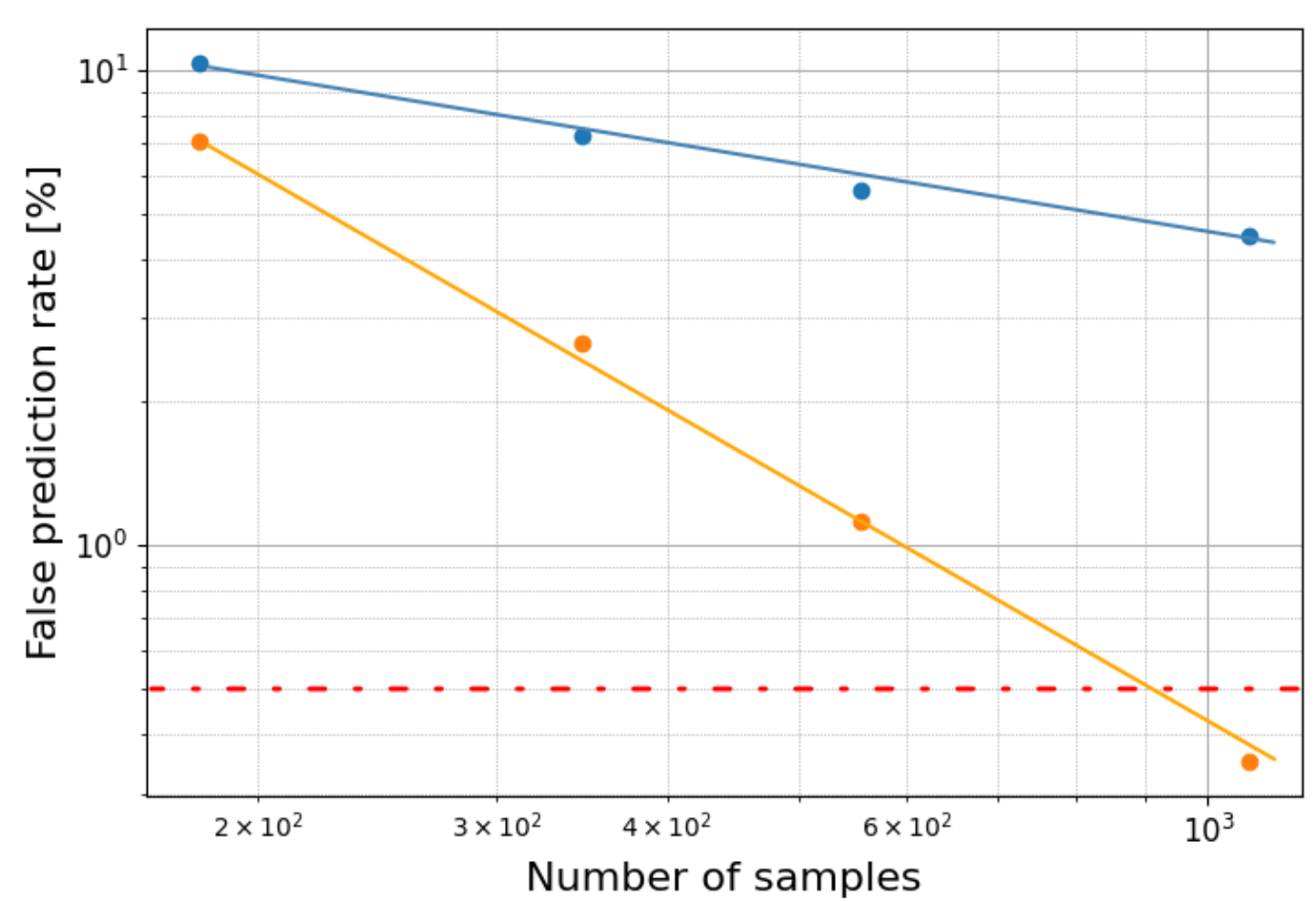
Generating synthetic data is a direct cost during the development of a new ML model. We have developed multiple algorithms and heuristics to limit the required amount of data to ensure that each model meets our accuracy requirements. The accompanying graph shows a comparison of two techniques used to generate a categorization model. The improved technique is shown in orange and demonstrates a false prediction rate of less than 0.5% with under 1000 samples.
Additionally, we can iterate between training and synthetic data generation to gradually increase model accuracy. This reduces the risk of overproducing synthetic data based on the topology of the phase space.
Machine learning lifecycle management
Our MAPSS approach results in a large number of small ML models which we manage along a defined lifecycle.
Model creation
After generating the synthetic training data, we create a ML model. One of the benefits of using synthetic data is generating validation and testing data which provides uniform sampling across key regions of interest, allowing interrogation of model accuracy to greater than 99.5% with a reasonable amount of data.
Model deployment
After passing accuracy requirements, the model is pushed directly into production. Because the system is modular, the deployment of a new model with new capabilities does not impact other, previously published models.
Model mixing
MAPSS modules are combined dynamically as customers input more requirements. The system maintains an inventory of each model, and how it can be used and paired with other models without introducing errors.
Model maintenance
If a customer’s request falls outside the model’s training range, it is possible to update the MAPSS module after generating the appropriate synthetic data.
A unique feature of the modules we develop is their longevity; because our models are built on core physics principles, our models never become obsolete.
